Бывает необходимо проектировать базы данных, записи которой содержат специальные символы, не входящие в какой-либо из алфавитов. Поэтому возникает надобность в использовании кодировки Юникод (UTF). О том как подружить MSSQL и UTF будет рассказано в данной статье.
Допустим требуется спроектировать базу данных (БД) для MSSQL содержащую англо-русский словарь. Соответственно поля этой таблицы будут следующими:
- Английское слово
- Транскрипция
- Перевод
Международный фонетический алфавит (International Phonetic Alphabet — IPA) из которого составляется транскрипция содержит специальные символы которые не в ходят ни английский алфавит, ни в русский (само собой), ни в какой-либо другой, например: ə, ð, æ, ʃ, ʌ и так далее.
В Microsoft SQL Server (MSSQL) присутствуют только национальные кодировки, то есть таблицы символов для конкретного языка. Если выполнить запрос:
|
1 |
SELECT * FROM ::fn_helpcollations() |
То можно увидеть список всех доступных кодировок. Список огромный (у меня 3885 строк).
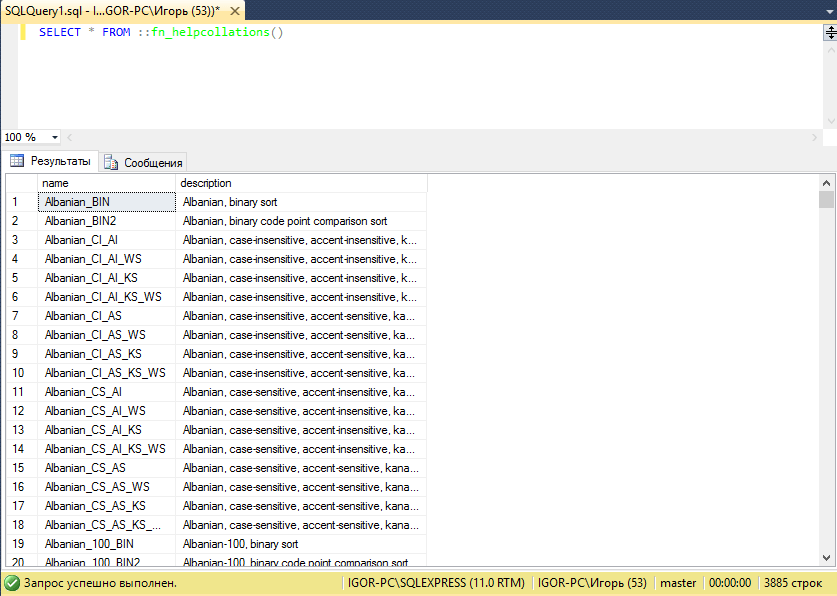
Все эти кодировки применимы в MSSQL к полям с однобайтовыми типами данных: char, varchar и text.
Чтобы установить нужную кодировку (например Latin1_General_CI_AI), необходимо воспользоваться оператором COLLATE:
|
1 2 3 4 5 6 7 8 |
create table dictionary ( id int not null, word varchar(30) COLLATE Latin1_General_CI_AI null, transcription varchar(40) null, translation text null, constraint PK_DICTIONARY primary key nonclustered (id) ) go |
В списке кодировок MSSQL отсутствует UTF (Юникод). Так как же настроить ее использование?
В MSSQL реализованы двухбайтовые типы данных: nchar, nvarchar и ntext. Как раз они и поддерживают использование всех символов кодировки UTF.
Использование типов данных nchar, nvarchar и ntext имеет серьезную особенность. Чтобы данные, заносимые в БД, корректно обрабатывались, нужно перед вставляемым значением дописать букву N — это сигнал для SQL сервера, что вводимые данные это Юникод.
|
1 |
INSERT INTO tableName VALUES (N'Значение') |
Рассмотрим пример. Создадим таблицу, где поле transcription имеет тип nvarchar:
|
1 2 3 4 5 6 7 8 |
create table dictionary ( id int not null, word varchar(30) null, transcription nvarchar(40) null, translation text null, constraint PK_DICTIONARY primary key nonclustered (id) ) go |
Добавление записи в таблицу будет происходить так:
|
1 |
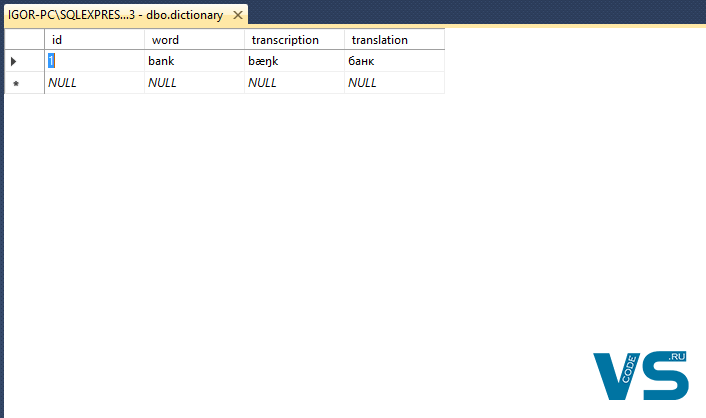
INSERT INTO dictionary VALUES (1, 'bank', N'bæŋk', 'банк') |
Видим, что данные корректно отображаются:
Спасибо за прочтение статьи о MSSQL и UTF!
Поделиться в соц. сетях: