В этой статье я расскажу про шифрование текста на языке C методом сдвига символов (также известный как шифр Цезаря). Пользователь вводит натуральное число n — это количество символов, на которое мы сдвигаем данный символ. Например, если n = 2, то буква ‘б’ превращается в букву ‘г’. Будем считать, что буквы идут по кругу, то есть за буквой ‘я’ следует буква ‘а’. Программа должна уметь как зашифровывать, так и расшифровывать текст. Шифровать будем только русские и английские буквы (другие символы: знаки препинания, пробелы и т.п. — шифровать не будем, оставим их без изменения). Ввод/вывод производим из файла.
Приступим к написанию программы. Подключим необходимые библиотеки и определим две константы — количество букв в английском и русском алфавитах соответственно.
Примечание. Константу RUS сделаем равной 32, потому что буква ‘ё’ в таблице символов ASCII в кодировке Windows 1251 находится за границей русского алфавита.
|
1 2 3 4 5 |
#include <stdio.h> #include <locale> #define ENG 26 #define RUS 32 |
Теперь напишем функцию, которая будет шифровать текст из входного файла. В качестве аргумента она будет принимать число n — количество символов, на которое сдвигать символы в тексте:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
void encrypt (int n) { FILE *fp1, *fp2; fopen_s(&fp1, "input.txt", "r"); fopen_s(&fp2, "output.txt", "w"); int flag; char c; c = getc(fp1); while (!feof(fp1)) { flag = 0; //обработан ли текущий символ if (c >= 'A' && c <= 'Z') { c = c + (n % ENG); if (c > 'Z') c = 'A' + (c - 'Z') - 1; fprintf (fp2, "%c", c); flag = 1; } if (c >= 'a' && c <= 'z') { c = c + (n % ENG); if (c > 'z') c = 'a' + (c - 'z') - 1; fprintf (fp2, "%c", c); flag = 1; } if (c >= 'А' && c <= 'Я') { c = c + (n % RUS); if (c > 'Я') c = 'А' + (c - 'Я') - 1; fprintf (fp2, "%c", c); flag = 1; } if (c>='а' && c<='я') { c = c + (n % RUS); if (c > 'я') c = 'а' + (c - 'я') - 1; fprintf (fp2, "%c", c); flag = 1; } if (!flag) fprintf (fp2, "%c", c); c = getc(fp1); } fclose (fp1); fclose (fp2); } |
Опишу по порядку, что происходит в этой функции. Открывает входной файл «input.txt» для чтения, открываем (или если он отсутствует, то создаем) выходной файл «output.txt» для записи. Функцией getc() будем по одному считывать символы из входного файла. Запускаем цикл с предусловием while (!feof(fp1)), функция в скобках проверяет, не достигли ли мы конца файла. В if’ах проверяем принадлежность считанного символа одной из групп символов, если считанный символ ‘c’ — это русская или английская буква, то выполняем ее шифрование, сдвигаем: c = c + (n % ENG). Остаток от деления на количество букв в алфавите берем для того, чтобы при n >= ENG убрать лишний «круг(и)» прохода по алфавиту. Если зашифрованная буква вышла за границы алфавита, то делаем круг и возвращаемся к началу: if (c > ‘Z’) c = ‘A’ + (c — ‘Z’) — 1;. Записываем символ в выходной файл.
Если же считанный символ ‘c’ не является буквой, а является другим символом (для контроля этого мы вводили переменную flag), то в этом случае выполнится условие if (!flag) fprintf (fp2, «%c», c); и мы запишем символ ‘c’ в выходной файл без изменения.
В конце функции закрываем файлы «input.txt» и «output.txt».
Теперь напишем функцию, которая расшифровывает текст. Здесь практически все то же самое, за исключение того, что теперь мы не «прибавляем» символы, а «вычитаем»:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
void decipher (int n) { FILE *fp1, *fp2; fopen_s(&fp1, "input.txt", "r"); fopen_s(&fp2, "output.txt", "w"); int flag; char c; c = getc(fp1); while (!feof(fp1)) { flag = 0; if (c >= 'A' && c <= 'Z') { c = c - (n % ENG); if (c < 'A') c = 'Z' - ('A' - c) + 1; fprintf (fp2, "%c", c); flag = 1; } if (c >= 'a' && c <= 'z') { c = c - (n % ENG); if (c < 'a') c = 'z' - ('a' - c) + 1; fprintf (fp2, "%c", c); flag = 1; } if (c >= 'А' && c <= 'Я') { c = c - (n % RUS); if (c < 'А') c = 'Я' - ('А' - c) + 1; fprintf (fp2, "%c", c); flag = 1; } if (c >= 'а' && c <= 'я') { c = c - (n % RUS); if (c < 'а') c = 'я' - ('а' - c) + 1; fprintf (fp2, "%c", c); flag = 1; } if (!flag) fprintf (fp2, "%c", c); c = getc(fp1); } fclose (fp1); fclose (fp2); } |
Теперь функция main:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
int main () { setlocale(LC_ALL,"Russian"); int n; printf ("Введите натуральное n: "); scanf_s ("%d", &n); getchar (); //нужен для того, чтобы поймать символ клавиши ENTER, нажатой при вводе числа n if (n < 1) return 0; printf ("Чтобы зашифровать текст введите a, расшифровать b: "); char c; scanf_s ("%c", &c, 1); if (c == 'a') encrypt (n); if (c == 'b') decipher (n); return 0; } |
Прокомментирую эту функцию. В начале подключим возможность отображения русских символов в консоли. Считаем число n, проверим натуральное ли оно. Далее спросим у пользователя, что ему необходимо: зашифровать или расшифровать текст, и выполним соответствующую операцию.
Демонстрация работы программы. Введем n = 2:
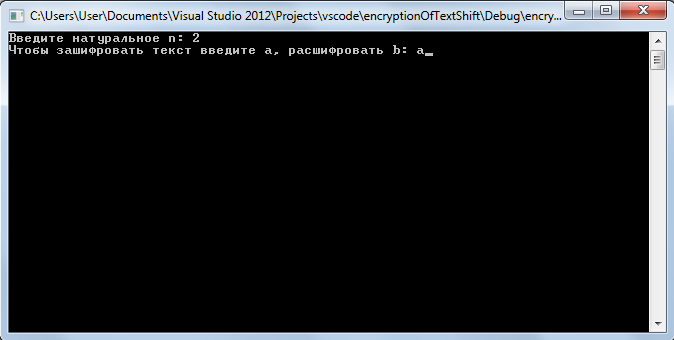
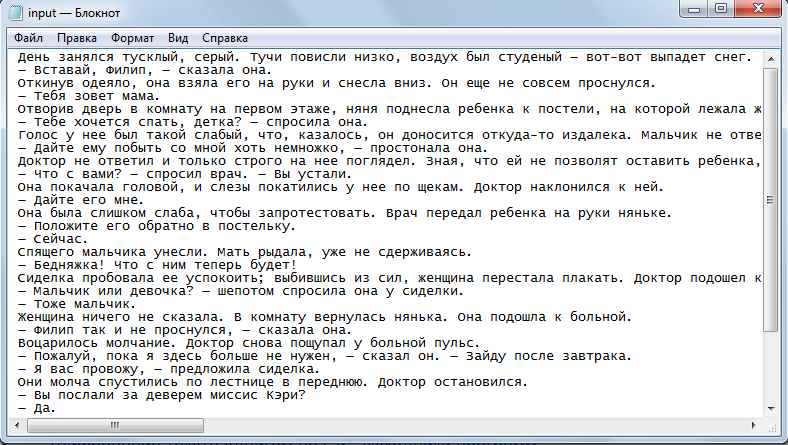
Исходный текст:
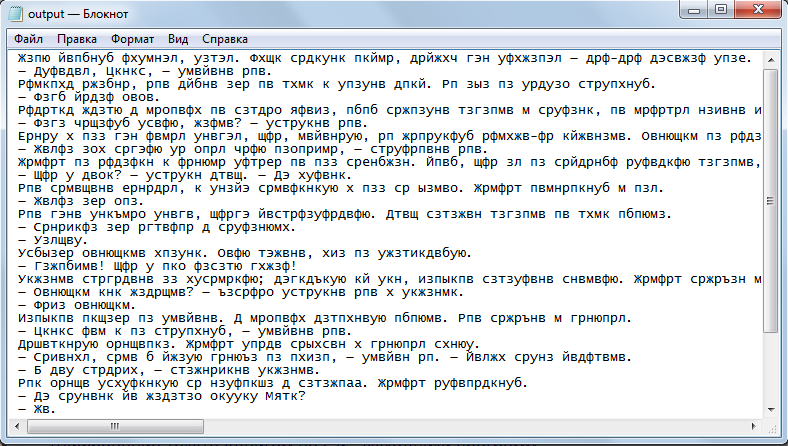
Получается такой зашифрованный текст:
Скачать исходник программы Шифр Цезаря можно, кликнув на кнопку ниже:
Скачать исходник
Поделиться в соц. сетях: